The ultimate Deal On Deepseek
페이지 정보
작성자 Kathryn 작성일 25-02-01 06:35 조회 4 댓글 0본문
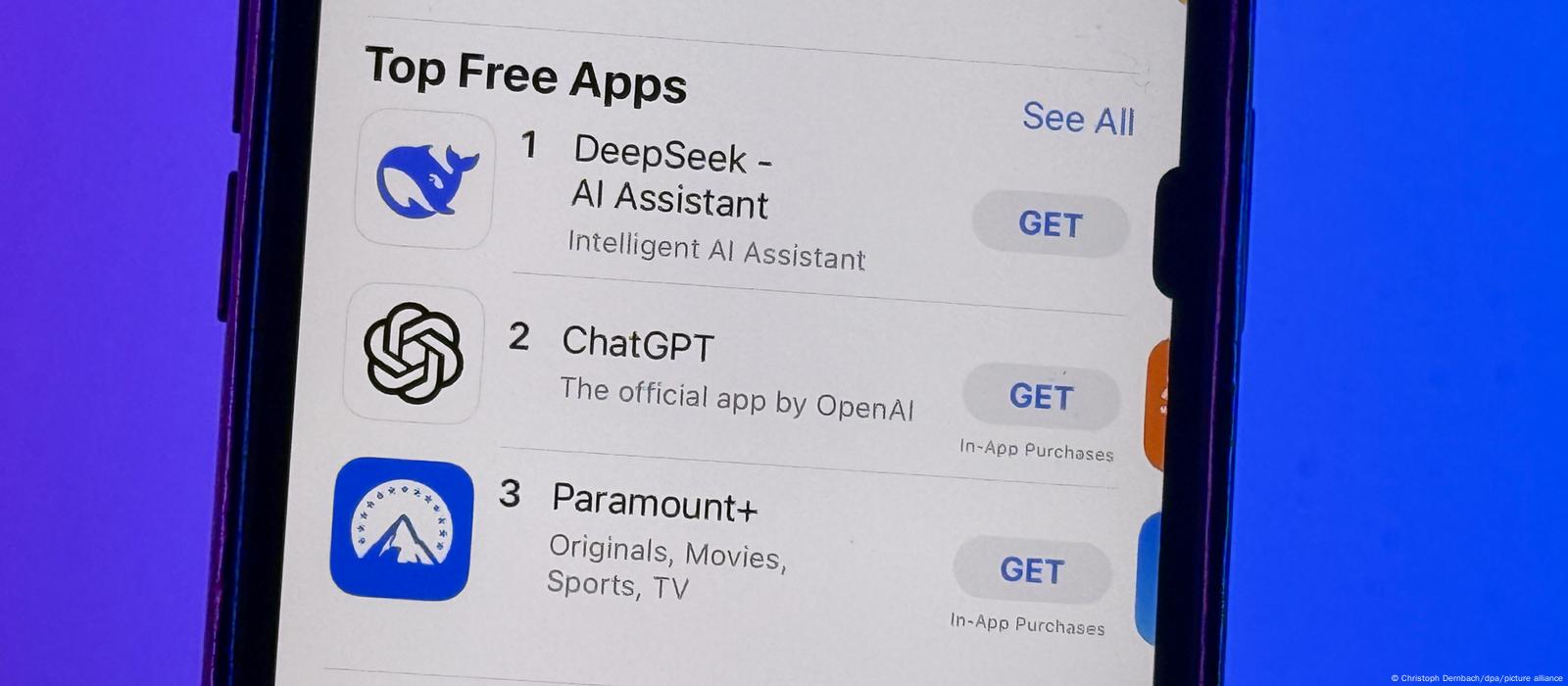
As per benchmarks, 7B and 67B DeepSeek Chat variants have recorded strong efficiency in coding, arithmetic and Chinese comprehension. Also, after we talk about a few of these improvements, that you must even have a model working. We are able to talk about speculations about what the massive model labs are doing. That was surprising as a result of they’re not as open on the language mannequin stuff. You'll be able to see these ideas pop up in open source the place they try to - if people hear about a good idea, they try to whitewash it and then brand deepseek Ai china it as their own. Therefore, it’s going to be hard to get open supply to build a greater mannequin than GPT-4, simply because there’s so many issues that go into it. There’s a good quantity of discussion. Whereas, the GPU poors are typically pursuing more incremental changes based on strategies which are identified to work, that might enhance the state-of-the-art open-supply models a average quantity. "DeepSeekMoE has two key concepts: segmenting experts into finer granularity for greater expert specialization and more correct knowledge acquisition, and isolating some shared specialists for mitigating data redundancy amongst routed specialists. One in every of the key questions is to what extent that information will end up staying secret, each at a Western agency competition degree, in addition to a China versus the remainder of the world’s labs level.
 How does the data of what the frontier labs are doing - despite the fact that they’re not publishing - find yourself leaking out into the broader ether? Thus far, regardless that GPT-four finished coaching in August 2022, there continues to be no open-source model that even comes close to the unique GPT-4, much less the November sixth GPT-four Turbo that was released. That's even better than GPT-4. The founders of Anthropic used to work at OpenAI and, in case you have a look at Claude, Claude is definitely on GPT-3.5 stage so far as performance, however they couldn’t get to GPT-4. There’s already a gap there and so they hadn’t been away from OpenAI for that long earlier than. There’s a very outstanding example with Upstage AI last December, the place they took an idea that had been in the air, utilized their very own title on it, and then revealed it on paper, claiming that concept as their own. And there’s just a bit little bit of a hoo-ha round attribution and stuff. That does diffuse information fairly a bit between all the large labs - between Google, OpenAI, Anthropic, no matter.
How does the data of what the frontier labs are doing - despite the fact that they’re not publishing - find yourself leaking out into the broader ether? Thus far, regardless that GPT-four finished coaching in August 2022, there continues to be no open-source model that even comes close to the unique GPT-4, much less the November sixth GPT-four Turbo that was released. That's even better than GPT-4. The founders of Anthropic used to work at OpenAI and, in case you have a look at Claude, Claude is definitely on GPT-3.5 stage so far as performance, however they couldn’t get to GPT-4. There’s already a gap there and so they hadn’t been away from OpenAI for that long earlier than. There’s a very outstanding example with Upstage AI last December, the place they took an idea that had been in the air, utilized their very own title on it, and then revealed it on paper, claiming that concept as their own. And there’s just a bit little bit of a hoo-ha round attribution and stuff. That does diffuse information fairly a bit between all the large labs - between Google, OpenAI, Anthropic, no matter.
They'd obviously some unique information to themselves that they introduced with them. Jordan Schneider: Is that directional data enough to get you most of the way in which there? Jordan Schneider: This concept of structure innovation in a world in which people don’t publish their findings is a extremely attention-grabbing one. deepseek ai simply confirmed the world that none of that is actually crucial - that the "AI Boom" which has helped spur on the American economy in latest months, and which has made GPU companies like Nvidia exponentially more wealthy than they have been in October 2023, may be nothing greater than a sham - and the nuclear energy "renaissance" along with it. You may go down the list when it comes to Anthropic publishing a number of interpretability research, but nothing on Claude. You'll be able to go down the listing and wager on the diffusion of knowledge by humans - natural attrition. Just by means of that natural attrition - folks go away all the time, whether it’s by choice or not by alternative, after which they discuss. We have some rumors and hints as to the structure, just because people speak.
So you possibly can have totally different incentives. So loads of open-source work is issues that you can get out shortly that get interest and get extra people looped into contributing to them versus a whole lot of the labs do work that's perhaps much less applicable within the quick time period that hopefully turns right into a breakthrough later on. DeepMind continues to publish various papers on every little thing they do, besides they don’t publish the fashions, so that you can’t really attempt them out. If your machine can’t handle each at the identical time, then try every of them and resolve whether or not you prefer an area autocomplete or a local chat expertise. The corporate launched two variants of it’s DeepSeek Chat this week: a 7B and 67B-parameter DeepSeek LLM, skilled on a dataset of 2 trillion tokens in English and Chinese. But it’s very hard to match Gemini versus GPT-4 versus Claude just because we don’t know the structure of any of these issues. That said, I do suppose that the massive labs are all pursuing step-change differences in model structure which can be going to actually make a difference. Its V3 mannequin raised some awareness about the company, though its content material restrictions round delicate subjects about the Chinese authorities and its management sparked doubts about its viability as an industry competitor, the Wall Street Journal reported.
- 이전글 Guide To Car Seat And Pram 2 In 1: The Intermediate Guide In Car Seat And Pram 2 In 1
- 다음글 Looking For Inspiration? Try Looking Up Boot Mobility Scooters
댓글목록 0
등록된 댓글이 없습니다.